Primary Work PageFriedman2026RecoveringLLMPersonaAccuracies152
DOI / Source10.5281/zenodo.20498699
Folderpapers/2026_RecoveringLLMPersona/
Overview
Extracted from the local README when available.
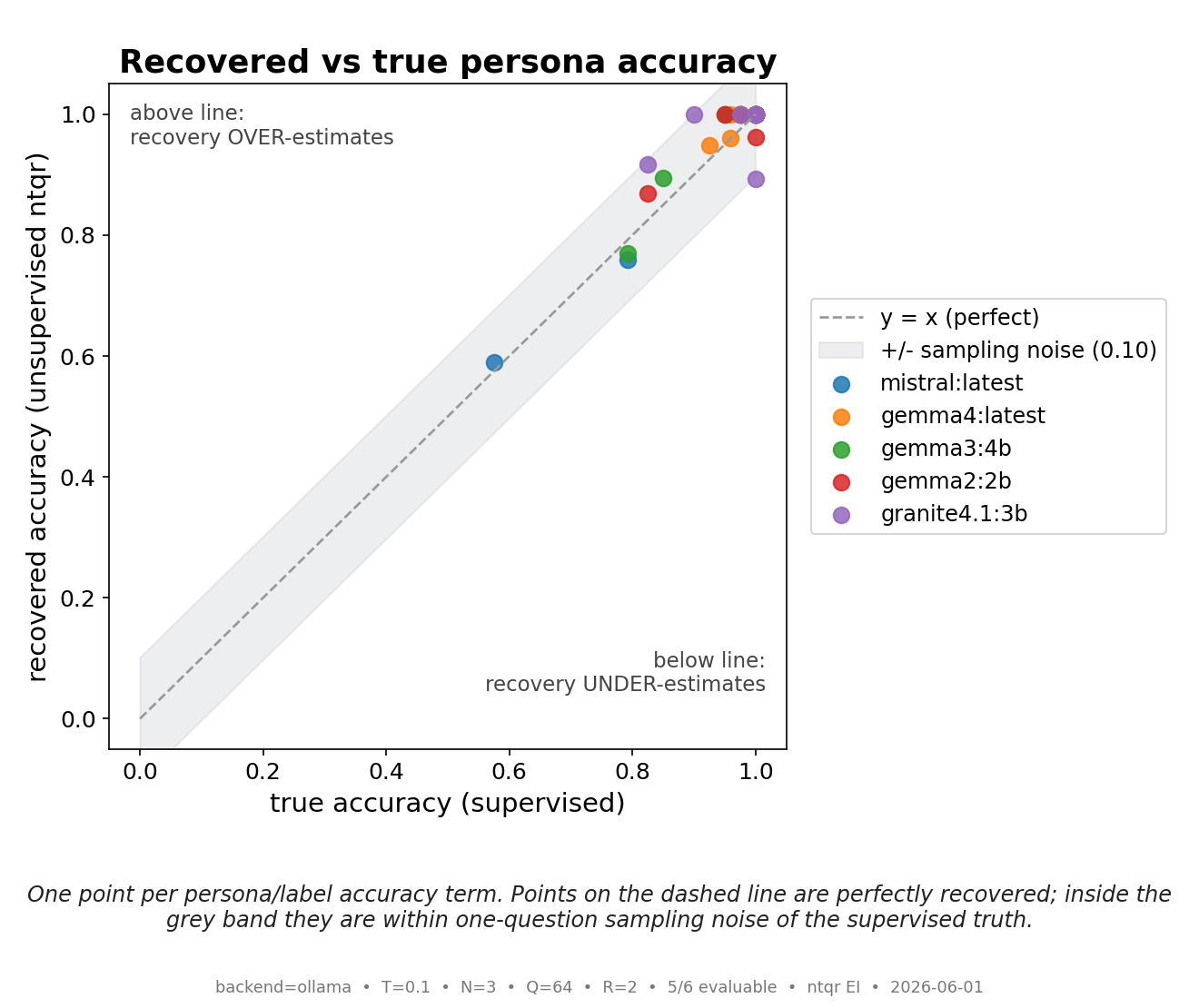
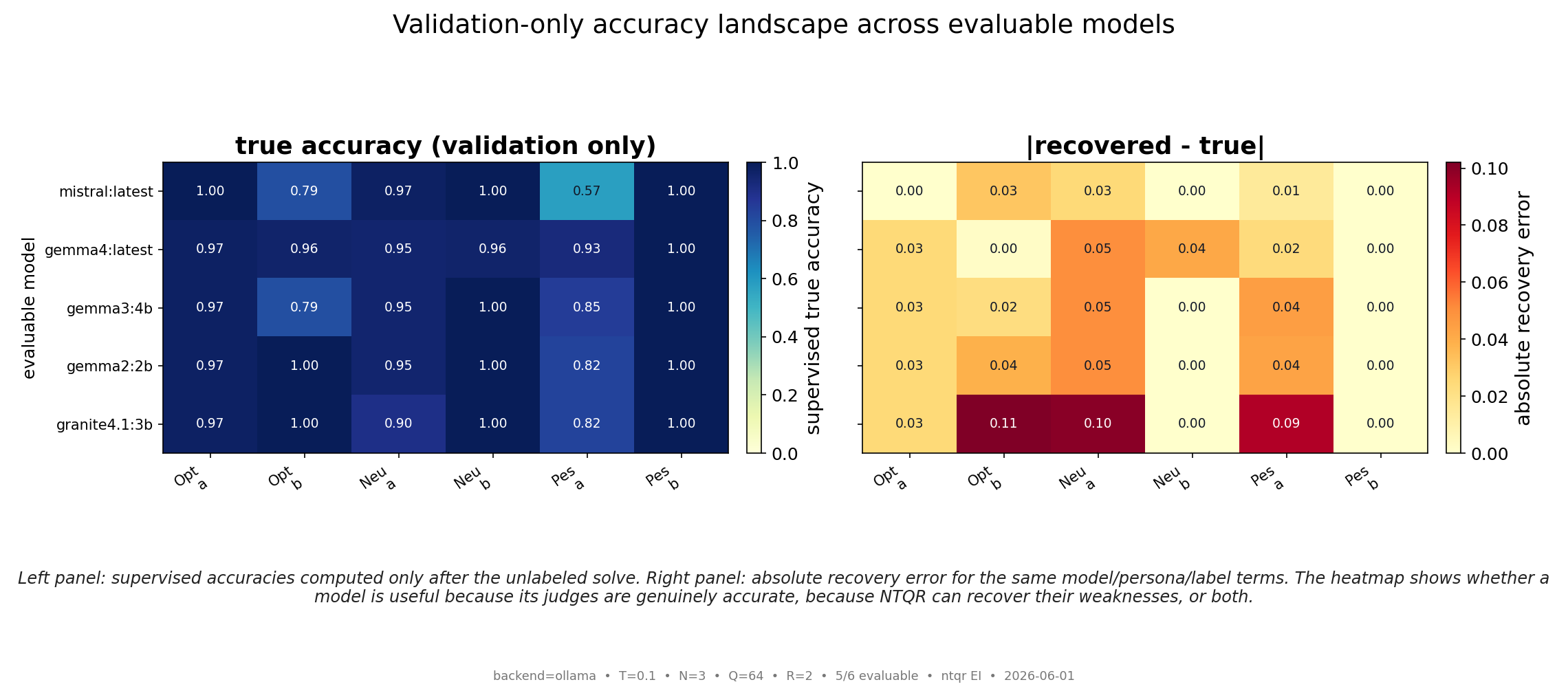
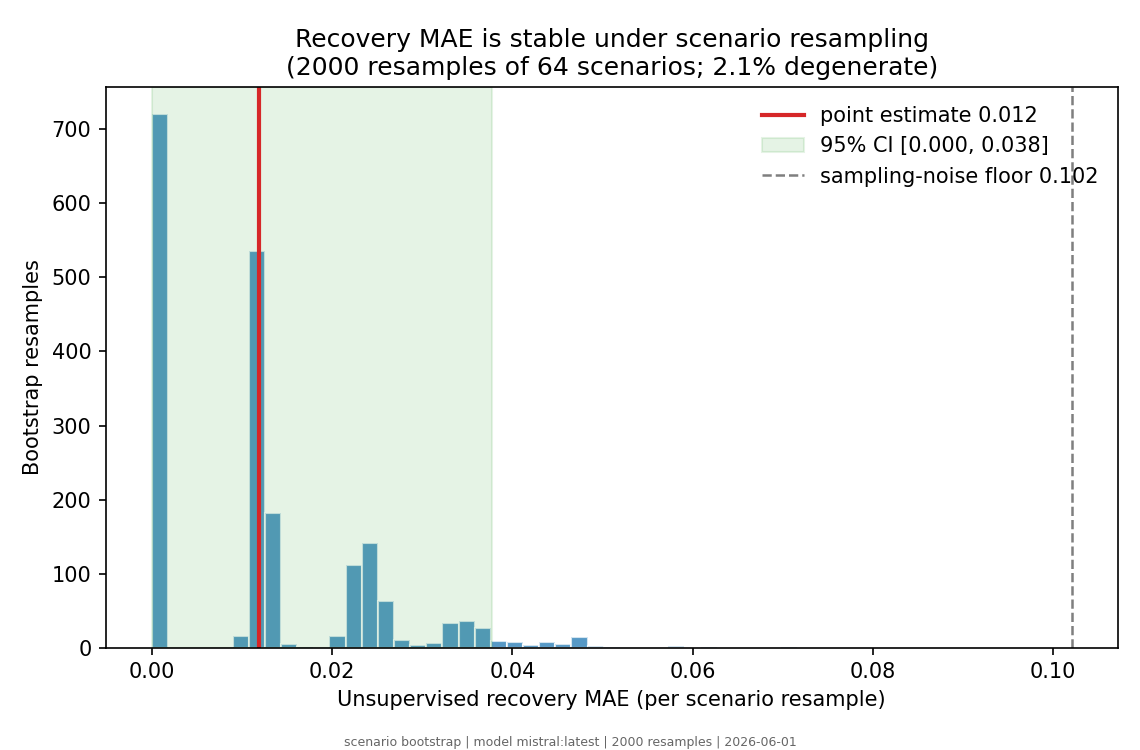
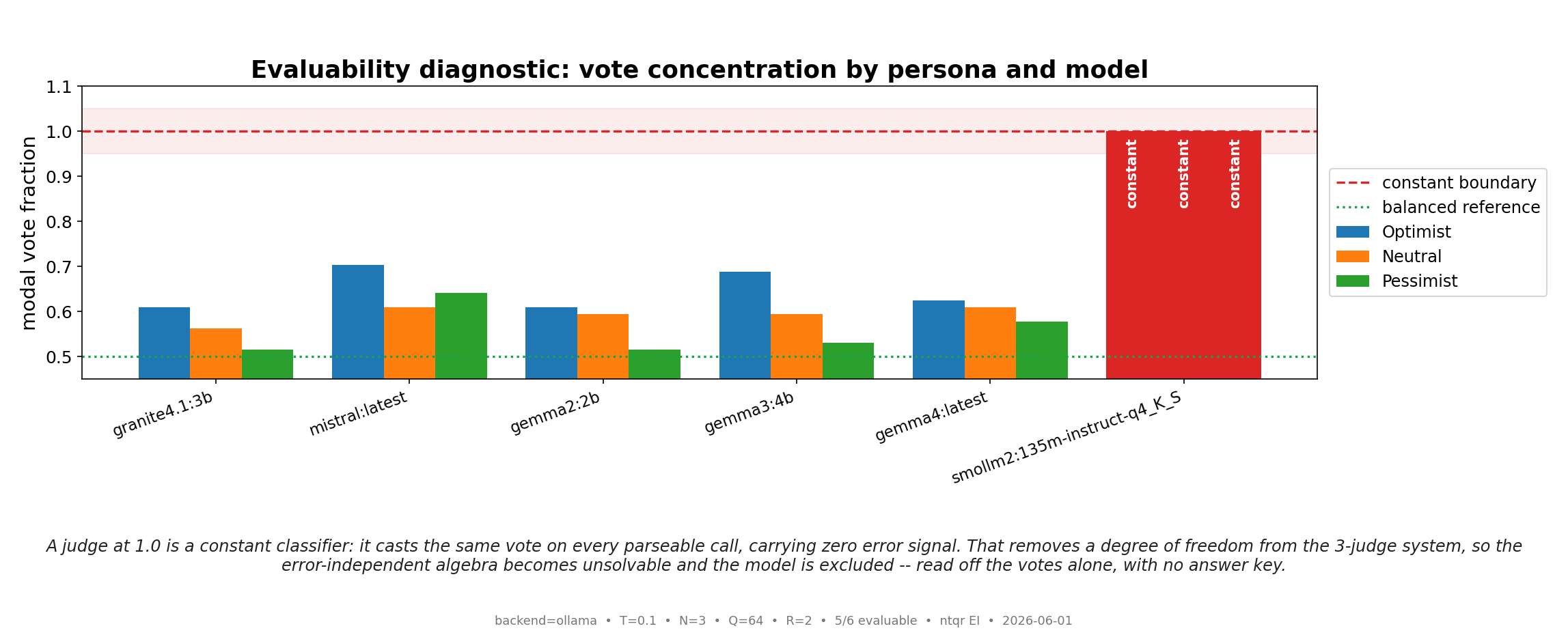
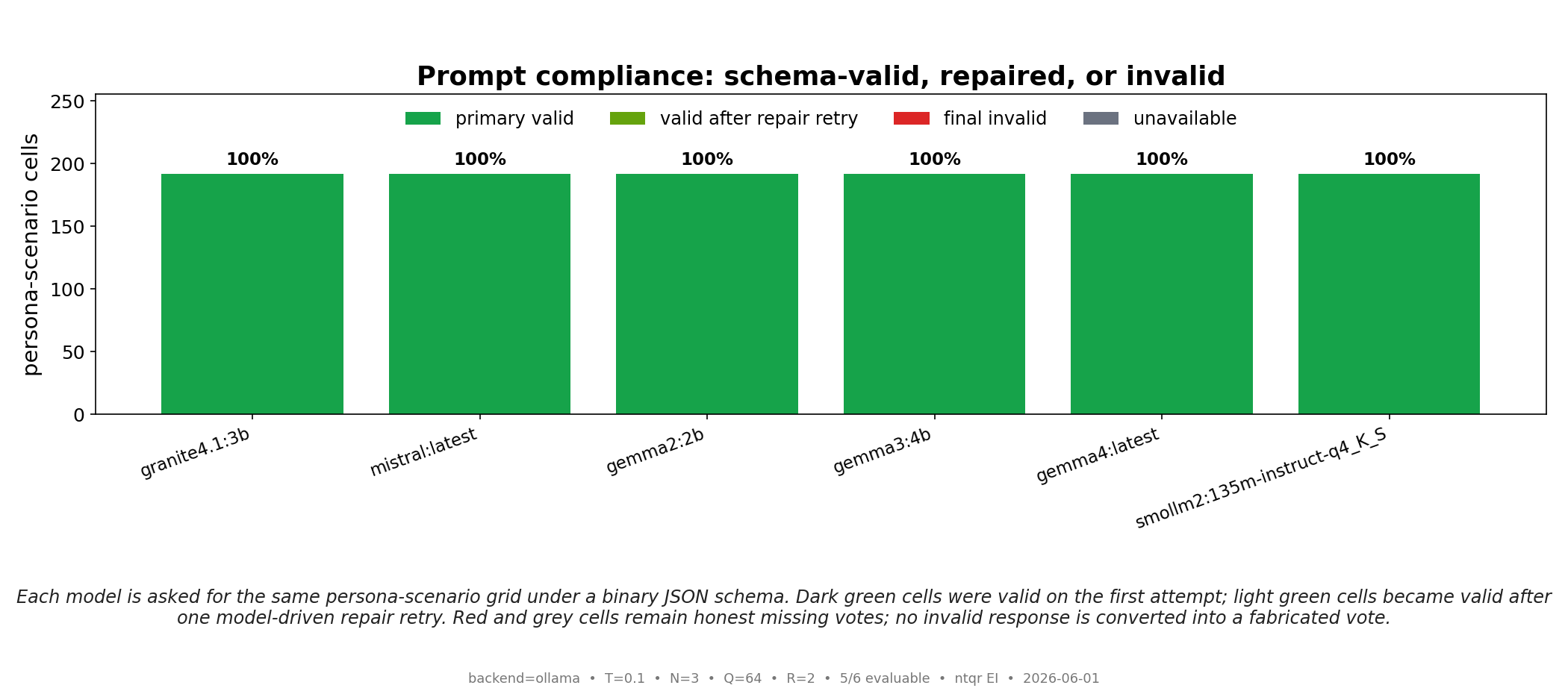
Algebraic (NTQR) evaluation infers how accurate a group of noisy classifiers was on a finite test using only their responses — no answer key. We test this end to end on real large language models. Three trader "personas" (optimistic, neutral, pessimistic), instantiated as system prompts, each make a binary bullish/bearish call on the same 64 market scenarios; we run the identical trio thr...
Artifacts
Tracked documentation and PDFs served directly from this folder.
PDF Files
- Friedman_2026_Recovering_e1196698.pdf 2,270,020 bytes
Extracted Content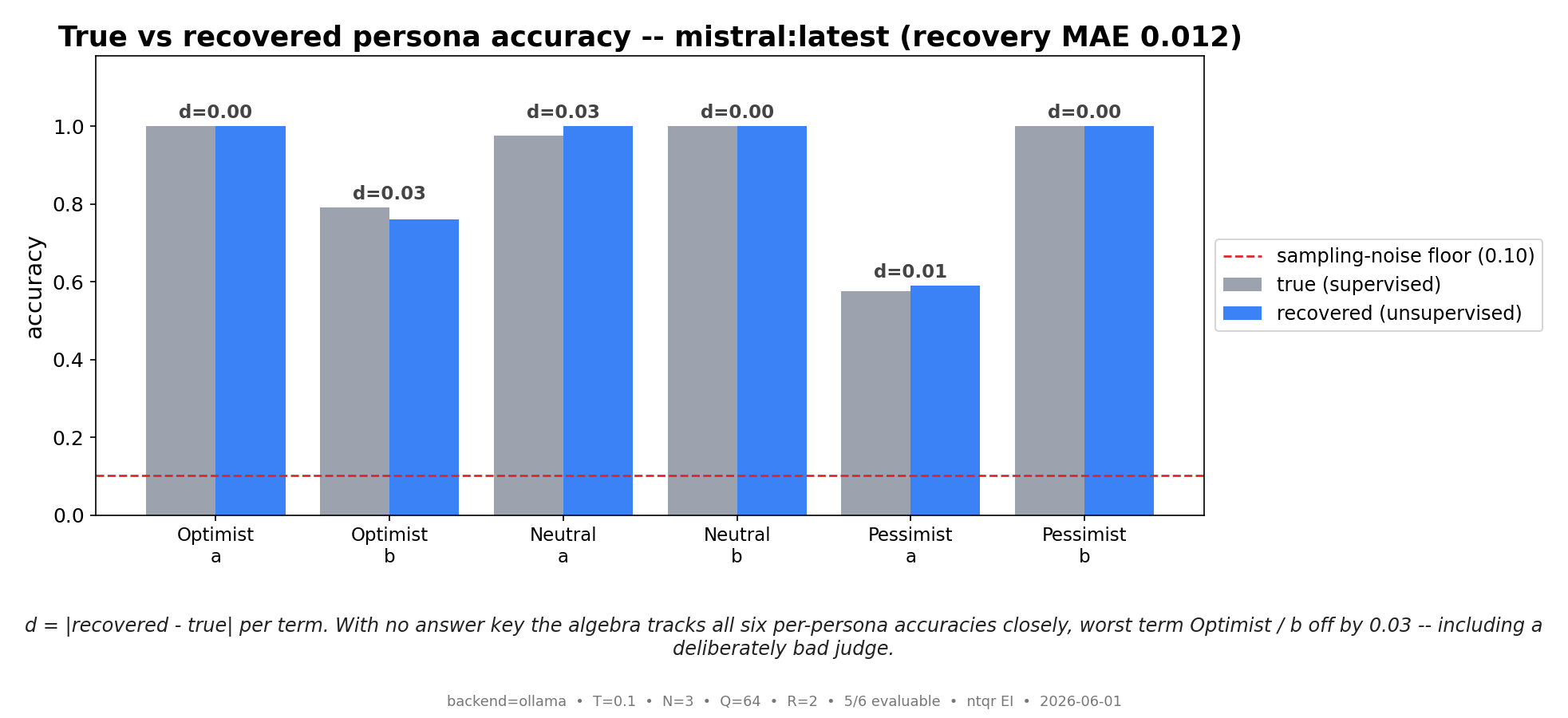
Extracted Images (16) — GitHub +10 more