Primary Work PageFriedman2026PolicyDistillationAsActive171
DOI / Source10.5281/zenodo.20747834
Folderpapers/2026_PolicyDistillationAs/
Overview
Extracted from the local README when available.
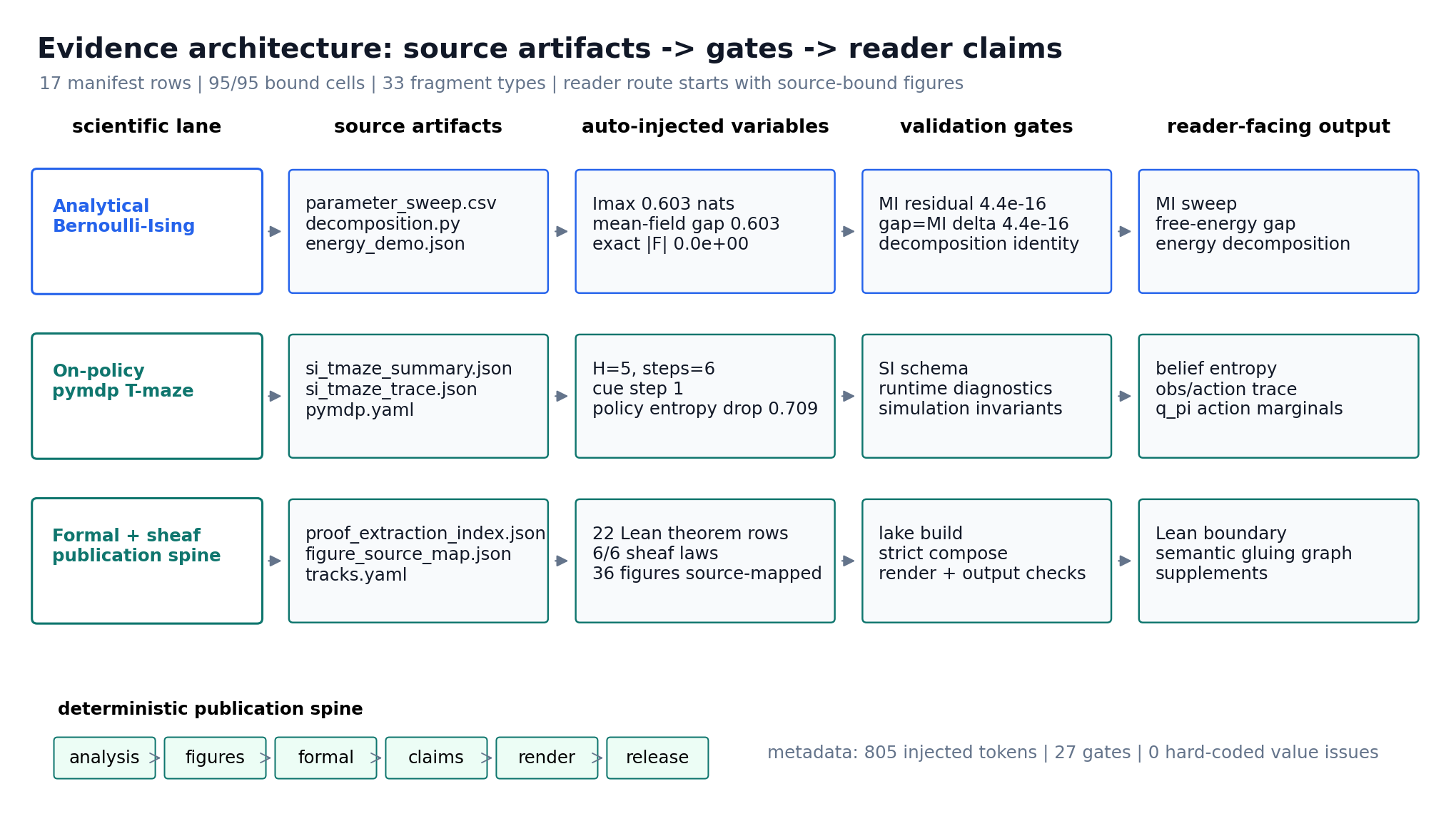
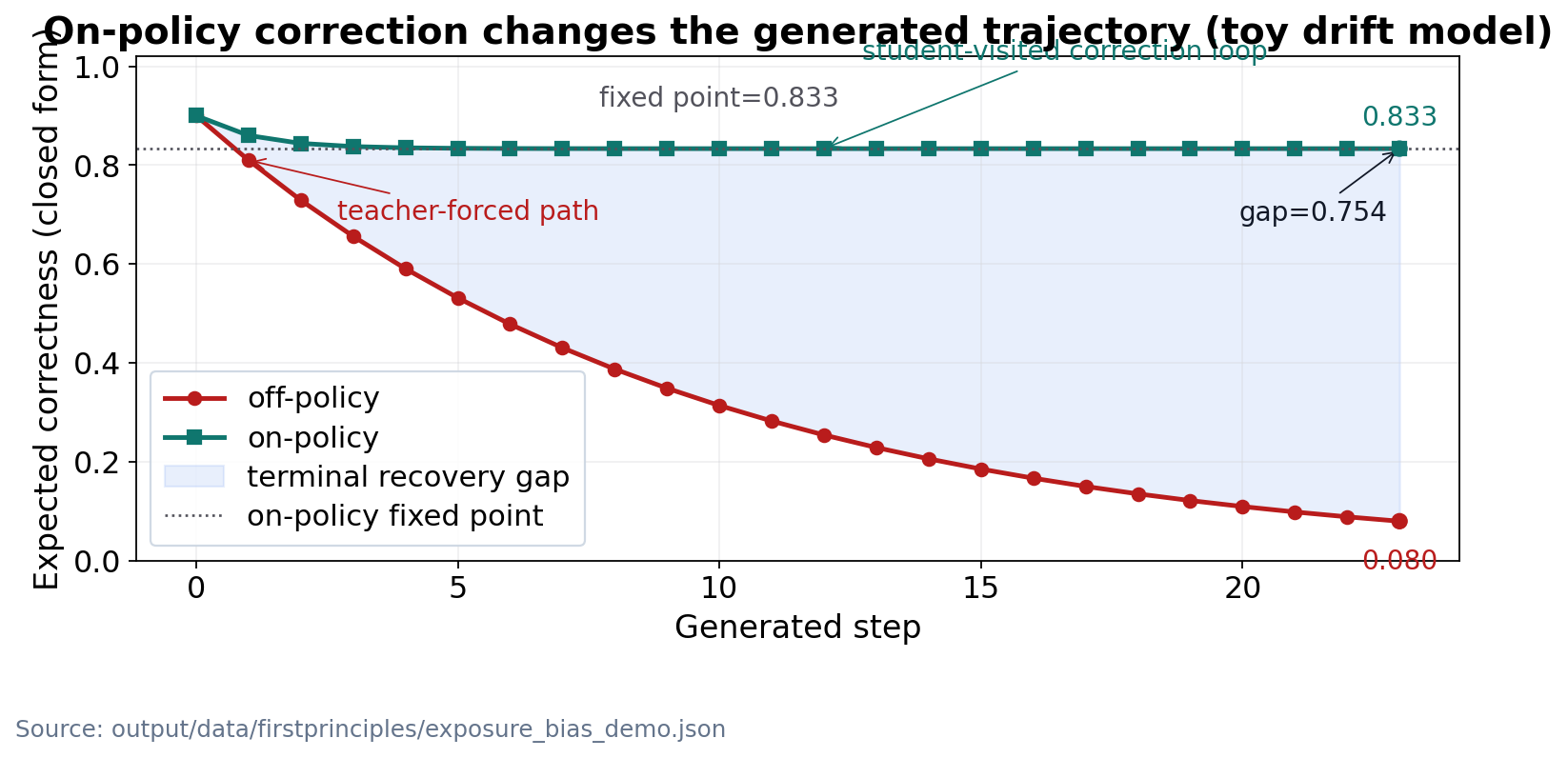
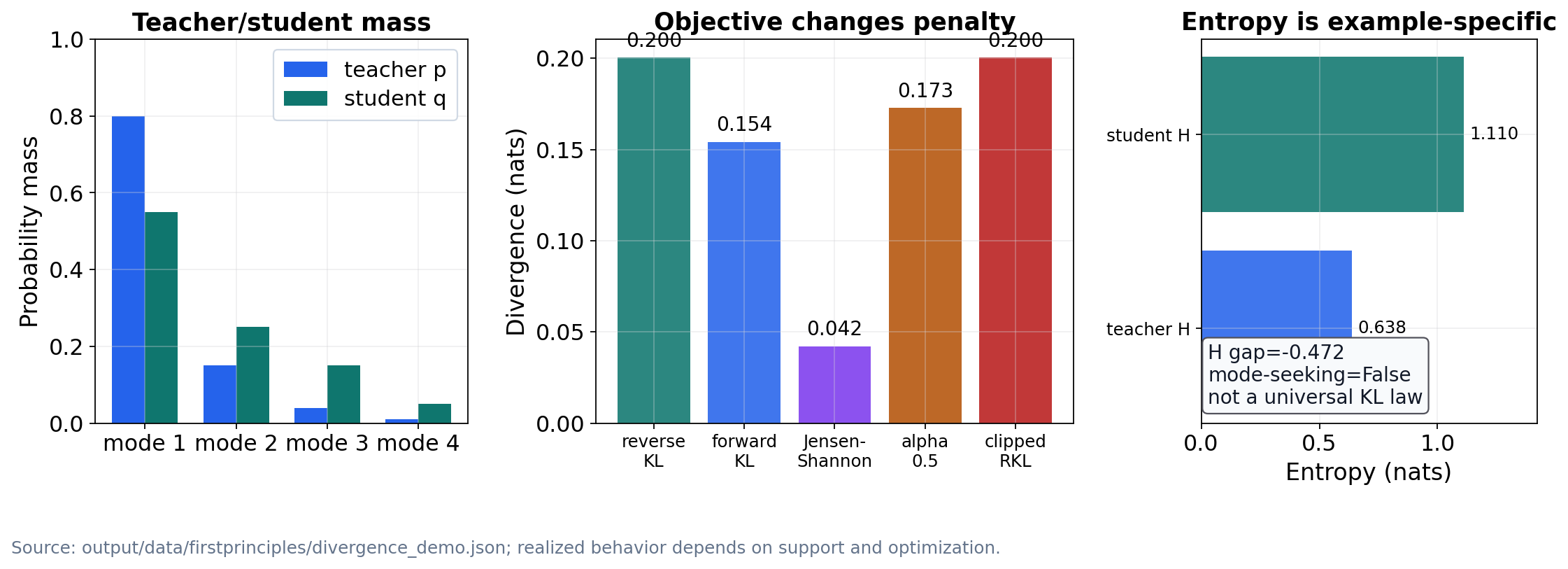
This paper formulates on-policy distillation as active inference in finite variational models, with exact claims only for declared objects and interpretive claims explicitly bounded outside them. In the construction, the intractable teacher policy plays the role of the generative model $p(o,s)$, the tractable student policy is the approximate posterior $q(s)$, and the per-token reverse-KL...
Artifacts
Tracked documentation and PDFs served directly from this folder.
PDF Files
- Friedman_2026_Onpolicy_c6b5ec49.pdf 8,102,450 bytes
Extracted Content


Extracted Images (39) — GitHub +33 more